Base de connaissance
Le système de Base de connaissances (RAG) de Rizlum vous permet de centraliser, de gérer et de configurer vos sources de données internes (documents, guides, procédures, FAQ). Ces données sont automatiquement traitées (vectorisées) pour servir de "cerveau" et fournir des réponses précises à vos agents.
Réutilisation du module : Une fois l'espace de connaissances créé, il peut être connecté de manière fluide à :
-
Un Agent Chat (Texte) : Pour répondre aux questions des utilisateurs sur un site web ou une application.
-
Un Agent Voice (Voix) : Pour alimenter en temps réel un conseiller virtuel lors d'appels téléphoniques.
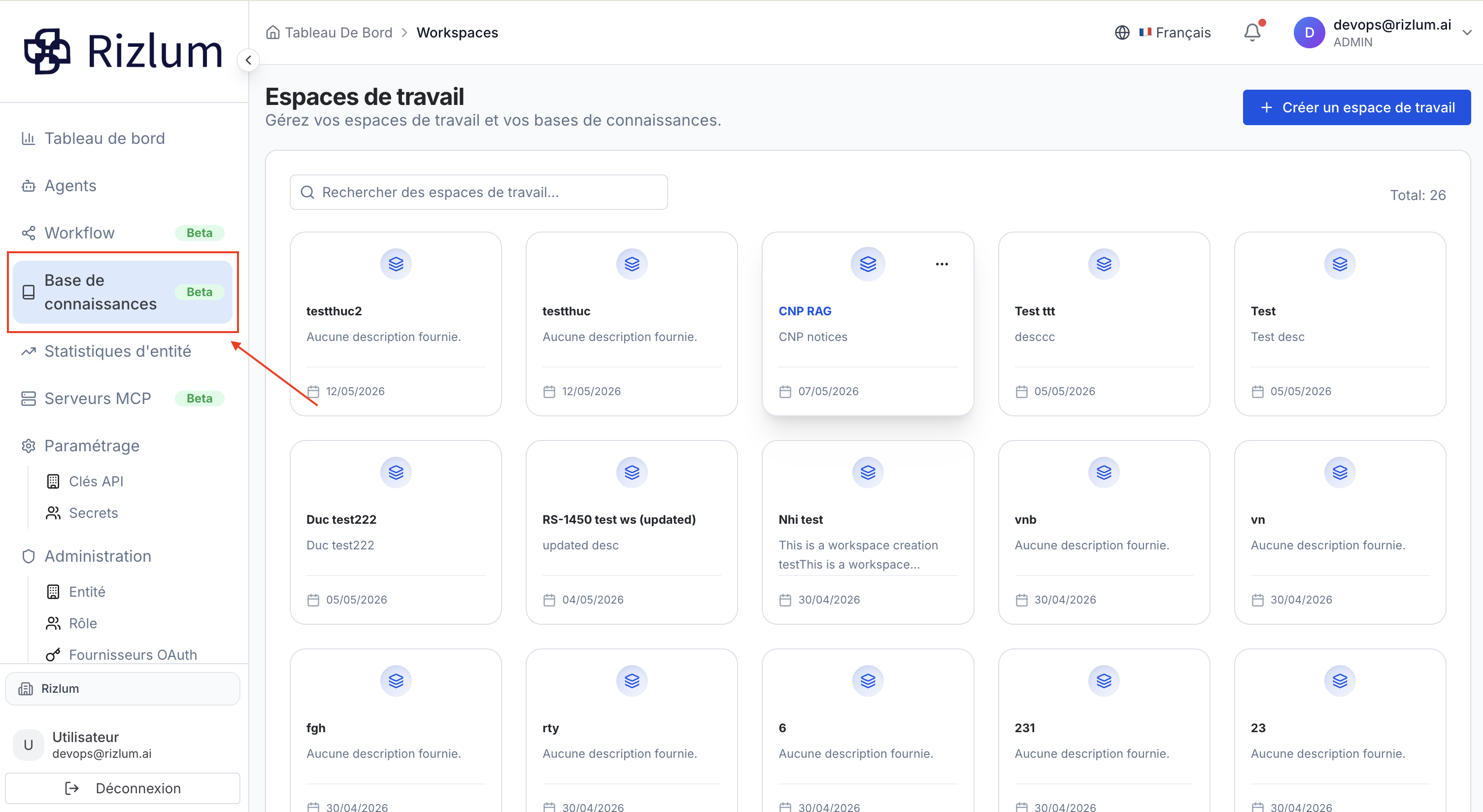
Depuis le menu latéral gauche, cliquez sur Espaces de travail pour accéder à l'écran de gestion centralisée. Cet écran regroupe l'ensemble de vos projets et bases de données.
-
Barre de recherche : Utilisez le champ « Rechercher des espaces de travail... » pour filtrer rapidement un espace par son nom.
-
Bouton de création : Cliquez sur « + Créer un espace de travail » (en haut à droite) pour initialiser une nouvelle base de données.
1. Créer un espace de travail
Cette section détaille les étapes pour configurer et initialiser un nouvel espace de travail (Workspace) via la fenêtre contextuelle dédiée. Cliquez sur « + Créer un espace de travail » (en haut à droite) pour initialiser une nouvelle base.
| Champ / Option | Statut | Description & Rôle pour l'Agent (Chat/Voice) |
|---|---|---|
| Nom de l'espace de travail | Obligatoire | Le titre de votre base de connaissances (Ex: Assurance). Limité à 80 caractères. Ce nom permet de structurer vos données et de lier facilement la base à vos agents plus tard. |
| Description | Optionnel | Un résumé textuel du contenu de cet espace (Ex: Cet espace contiendra les contenus et documents relatifs à l'assurance.). Il aide l'équipe à identifier rapidement l'usage de ce projet. |
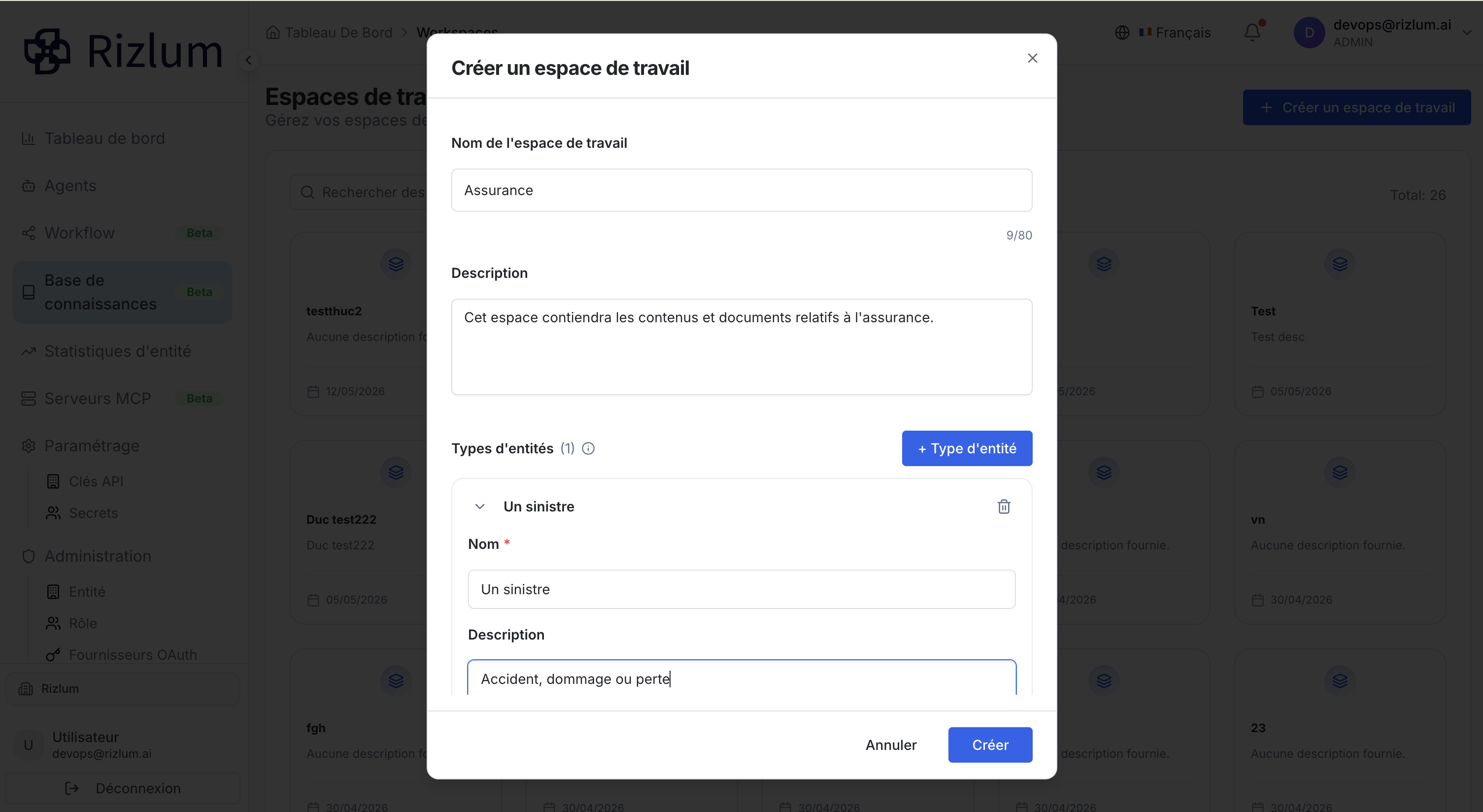
| Types d'entités | Optionnel | Permet de définir des catégories ou des concepts clés spécifiques à votre domaine métier pour guider le comportement et la compréhension de l'agent. |
Attention : le champ «Type d'entités».
Les types d'entités permettent de structurer les connaissances métiers que vos agents (Chat ou Voice) doivent savoir identifier de manière prioritaire dans les documents ou dans les intentions de l'utilisateur.
Ajouter une entité : Cliquez sur le bouton bleu « + Type d'entité ».
| Composant de l'entité | Statut / Action | Description & Rôle pour l'Agent (Chat/Voice) |
|---|---|---|
| Nom | Obligatoire | Donnez un libellé clair à l'entité (exemple: Un sinistre). Ce nom sert de repère pour l'algorithme. |
| Description | Optionnel | Définissez ce que représente cette entité (exemple: Accident, dommage ou perte). Cela aide l'IA sous-jacente à mieux contextualiser ce concept. |
| Supprimer | Action | Vous pouvez retirer une entité à tout moment en cliquant sur l'icône de la corbeille située à droite de celle-ci. |
Validation et enregistrement
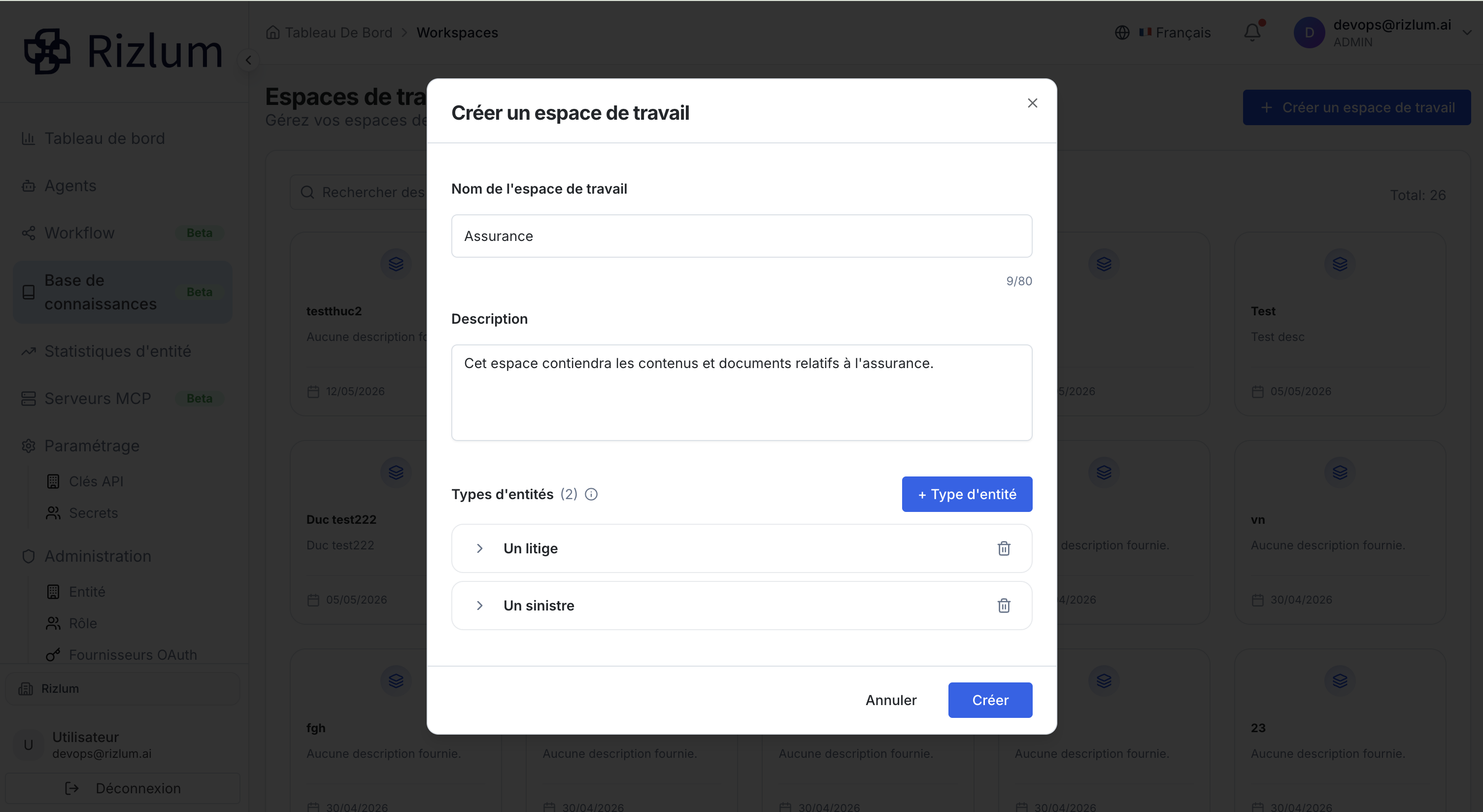
Une fois tous les champs complétés, deux actions sont possibles au bas de la pop-up :
| Action | Comportement du système | Résultat pour l'Utilisateur / Agent |
|---|---|---|
| Annuler | Interrompt le processus actuel et ferme la fenêtre contextuelle (Popup). | Aucune modification n'est enregistrée, retour à l'écran précédent. |
| Créer | Valide la configuration et enregistre les données saisies. | Le nouvel espace de travail est instantanément généré sous forme de carte (Card) sur le tableau de bord, prêt à recevoir vos documents (RAG). |
Après la validation, l'ensemble des espaces de travail configurés est répertorié sur la page principale sous forme de tableau de bord dynamique. Cette interface centralisée offre des outils de filtrage et de navigation avancés pour piloter vos différentes bases de connaissances (RAG).
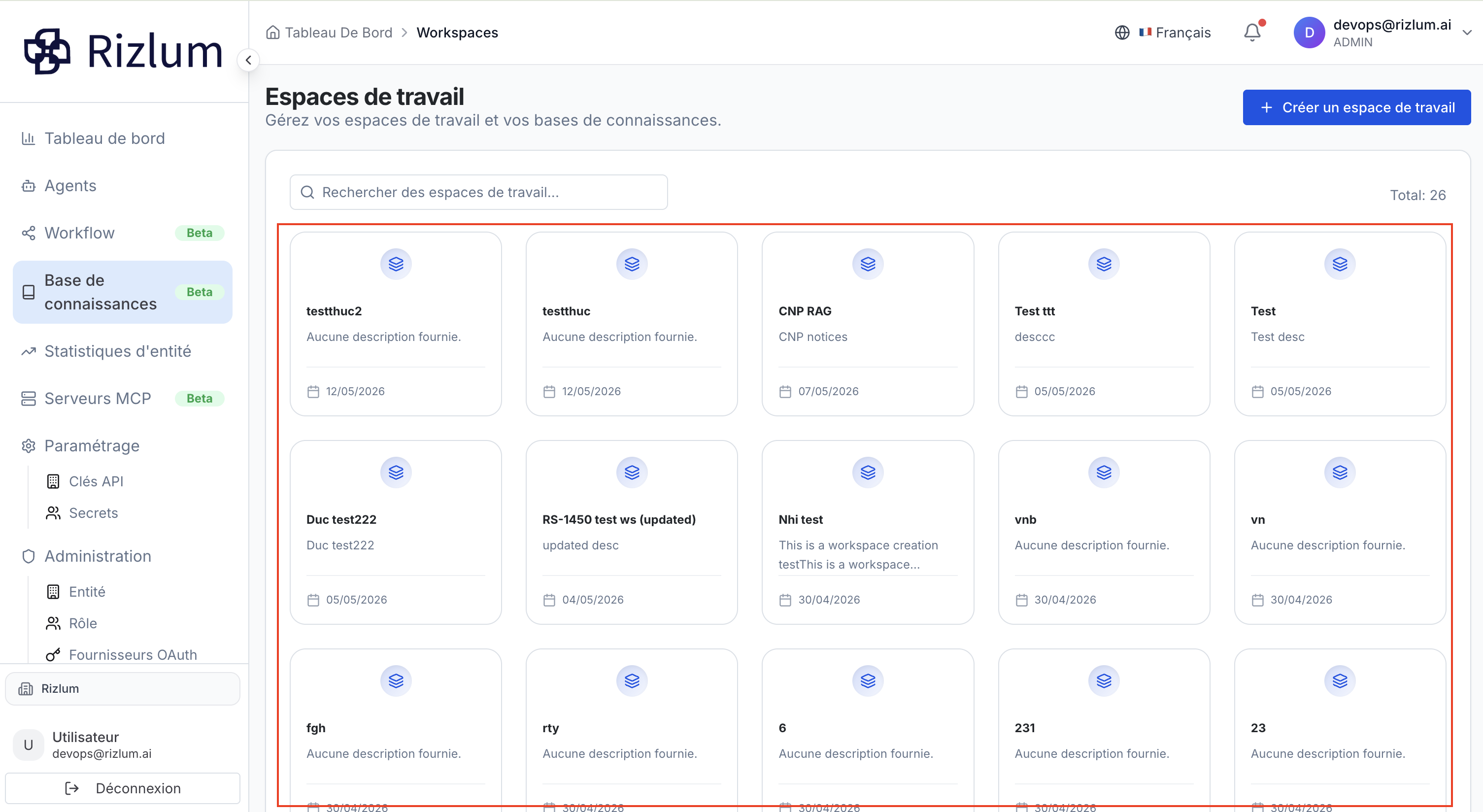
2. Ajouter un fichier dans un espace
Une fois l'espace de travail sélectionné, l'interface bascule sur le module d'administration de la base de connaissances. Cet écran permet d'ingérer, de suivre le traitement sémantique et le cycle de vie de vos documents sources (fichiers, textes bruts, URL).
2.1. Tableau de bord de suivi de l'indexation
Quatre indicateurs clés (KPI) permettent de piloter l'état du pipeline RAG en temps réel :
| Indicateur | Description Métrique | Statut Opérationnel pour l'Agent |
|---|---|---|
| Total des sources | Somme globale de tous les documents injectés dans l'espace. | Évalue la volumétrie brute de la base. |
| Indexé | Nombre de sources ayant subi avec succès le découpage (splitting) et la vectorisation. | Disponibles immédiatement pour l'interrogation par les agents Chat/Voice. |
| En cours | Sources actuellement en cours de traitement par le pipeline d'IA (Embedding). | En attente de traitement. Non encore accessibles par l'agent. |
| Échoué | Sources n'ayant pas pu être indexées (format corrompu, problème d'encodage). | Inaccessibles. Nécessitent une vérification ou un nouvel import. |
2.2. Contrôles d'Ingestion et de Filtrage des Données
L'interface met à disposition un ensemble d'outils pour administrer efficacement le catalogue de fichiers :
| Composant de l'interface | Type d'action | Rôle et Comportement du Système |
|---|---|---|
| Moteur de recherche local | Filtrage par mots-clés | Filtre instantanément la liste des documents affichés selon leur nom de fichier. |
| Filtre « Tous les types » | Menu déroulant sémantique | Segmenter l'affichage selon la nature de la source (ex : Fichiers, Textes, Liens Web). |
| Filtre « Tous les statuts » | Menu déroulant d'état | Permet d'isoler rapidement les documents en succès, en cours ou en échec (Terminé, En cours, Échoué). |
| Supprimer la sélection | Action groupée (Bulk action) | Permet de purger définitivement un ou plusieurs documents sélectionnés via leur case à cocher. Les vecteurs associés sont instantanément retirés de la mémoire de l'agent. |
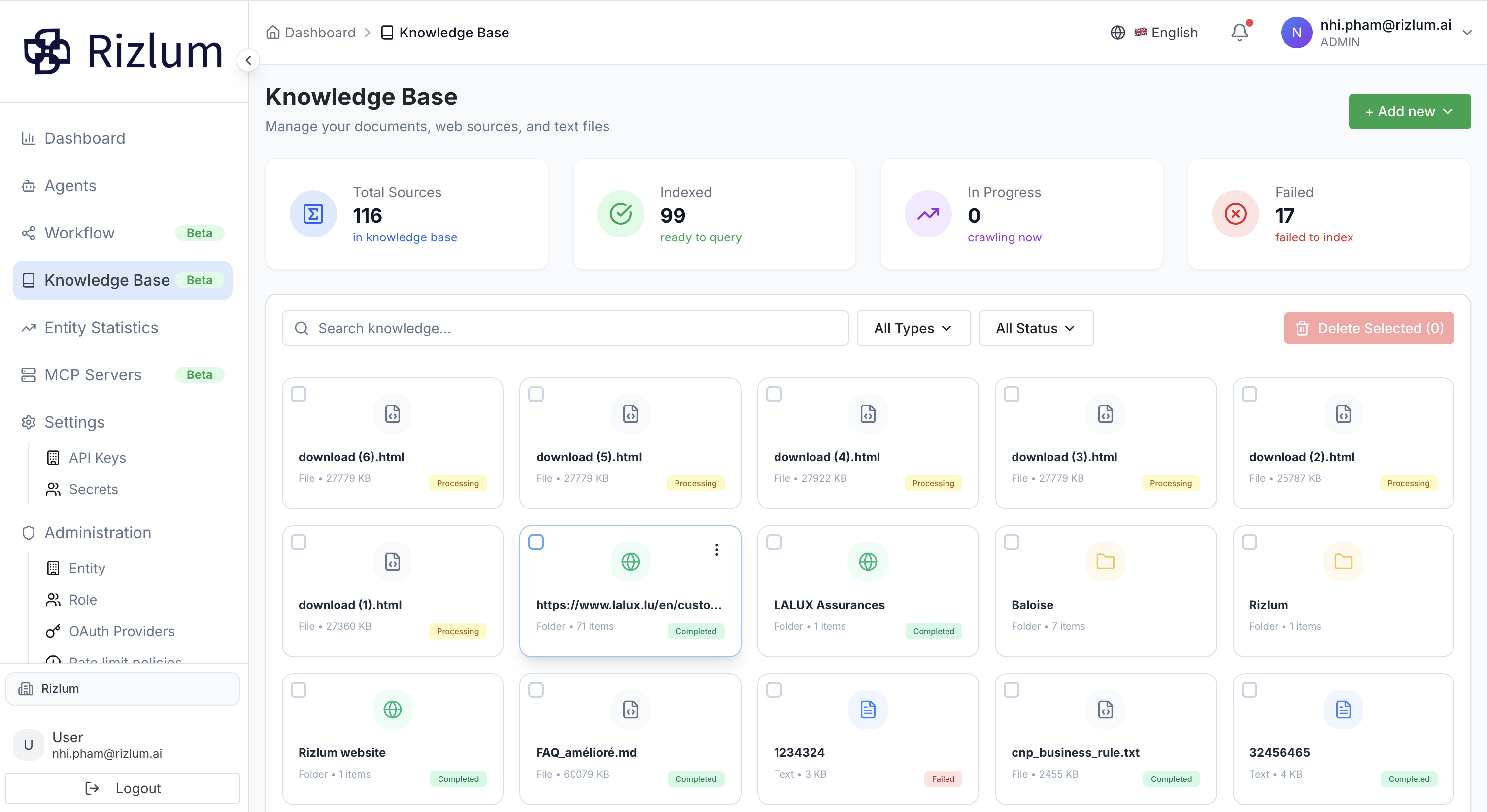
2.3. Ajouter un document
Bouton « + Ajouter » : Déclenche le menu d'importation pour téléverser de nouveaux documents, coller du texte ou soumettre des URLs web.
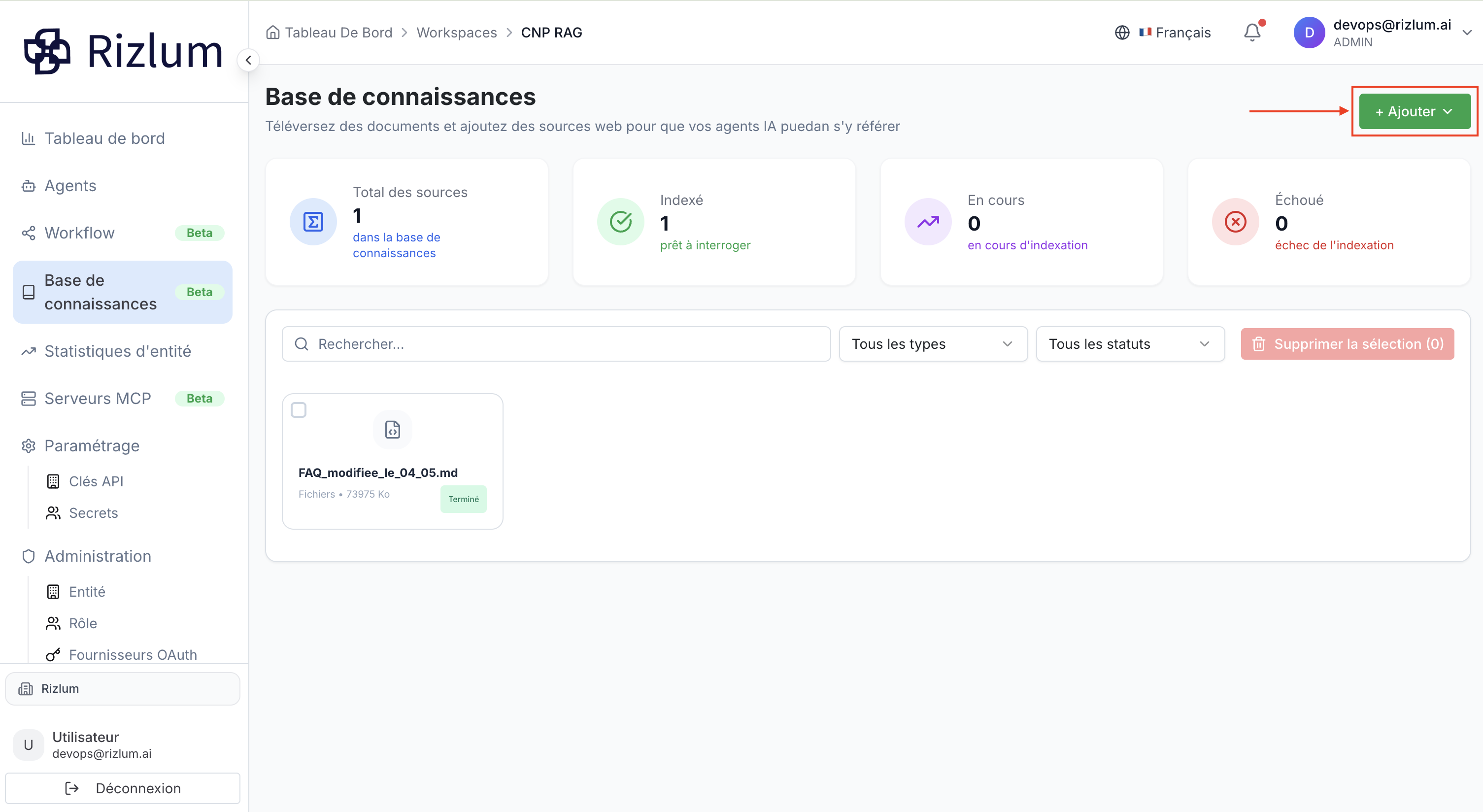
2.3.1. Ajouter un fichier
Le pipeline d'ingestion de la base de connaissances (RAG) prend en charge exclusivement les formats listés ci-dessous :
| Catégorie | Extensions Supportées | Tag de Style Sémantique | Type de Traitement et Comportement RAG |
|---|---|---|---|
| Documents Textuels & Bureautique | pdf, md, txt, docx, pptx, xlsx, rtf, odt, tex, epub, html, htm |
Document / Texte |
Extraction de la couche texte et découpage par paragraphes sémantiques (Chunking) pour l'apprentissage de l'agent. |
| Données & Fichiers Structurés | csv, json, xml, yaml, yml |
Données Structurées |
Analyse syntaxique (Parsing) des objets et des tableaux pour permettre des requêtes précises sur des bases de données textuelles. |
| Configuration & Systèmes | log, conf, ini, properties, sql, bat, sh |
Système & Configuration |
Extraction brute des variables, des schémas de données et des scripts pour les bases de connaissances techniques. |
| Code Source & Développement | c, cpp, py, java, js, ts, swift, go, rb, php, css, scss, less |
Code Source |
Extraction des structures de code, des fonctions et des commentaires pour l'assistance technique et le développement. |
Vous pouvez glisser-déposer plusieurs fichiers à la fois. Maximum : 10 fichiers par envoi. Taille maximale : 21 Mo par fichier.
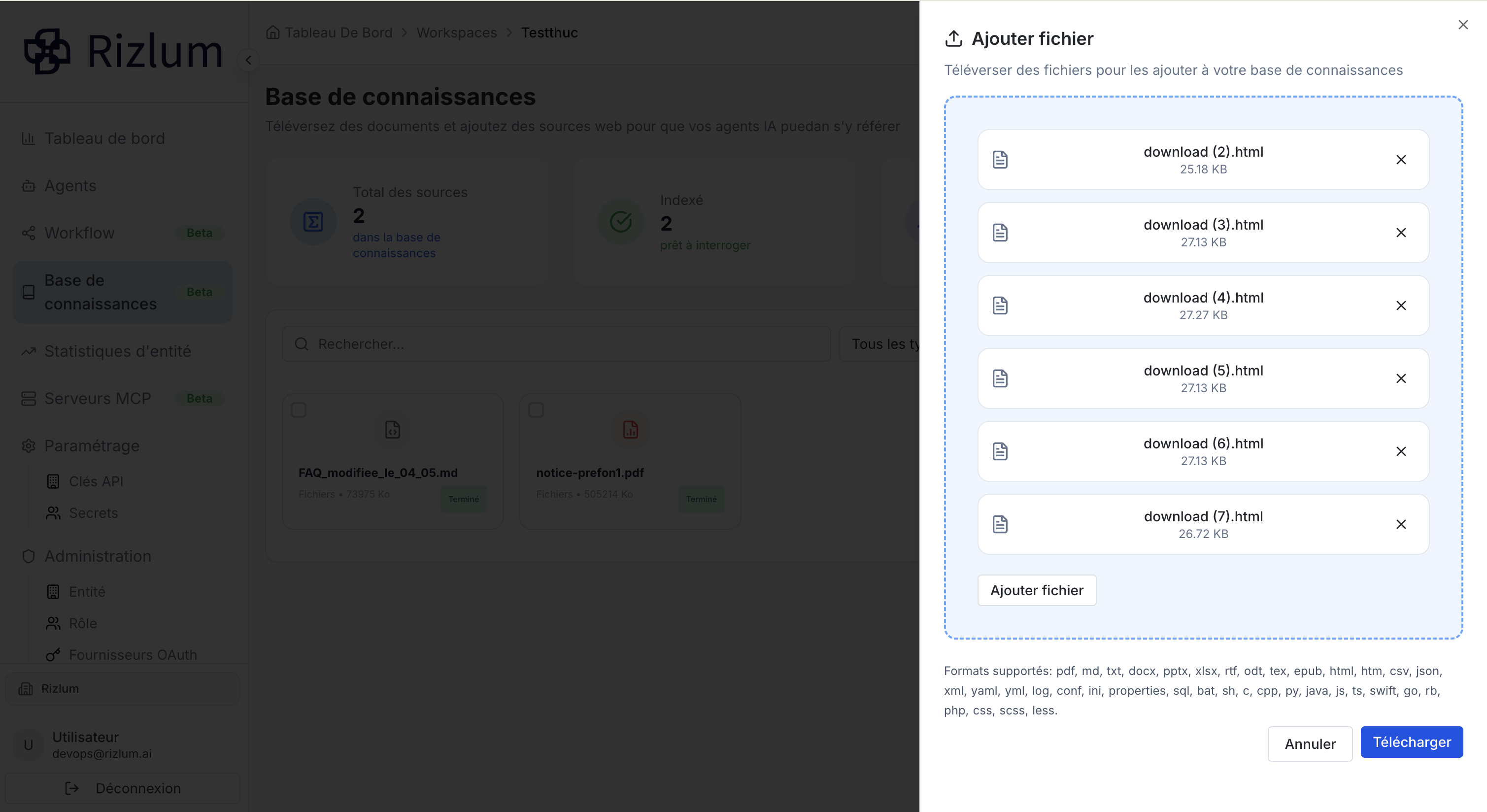
Après le téléchargerment, les fichiers s'afficheront dans la liste des documents.
2.3.2. Ajouter une URL
L'interface « Ajouter URL » permet d'extraire et de vectoriser directement le contenu textuel de pages web pour enrichir la base de connaissances (RAG). Ce processus s'effectue en deux phases principales : la découverte des liens (Crawling) et la validation de l'indexation.
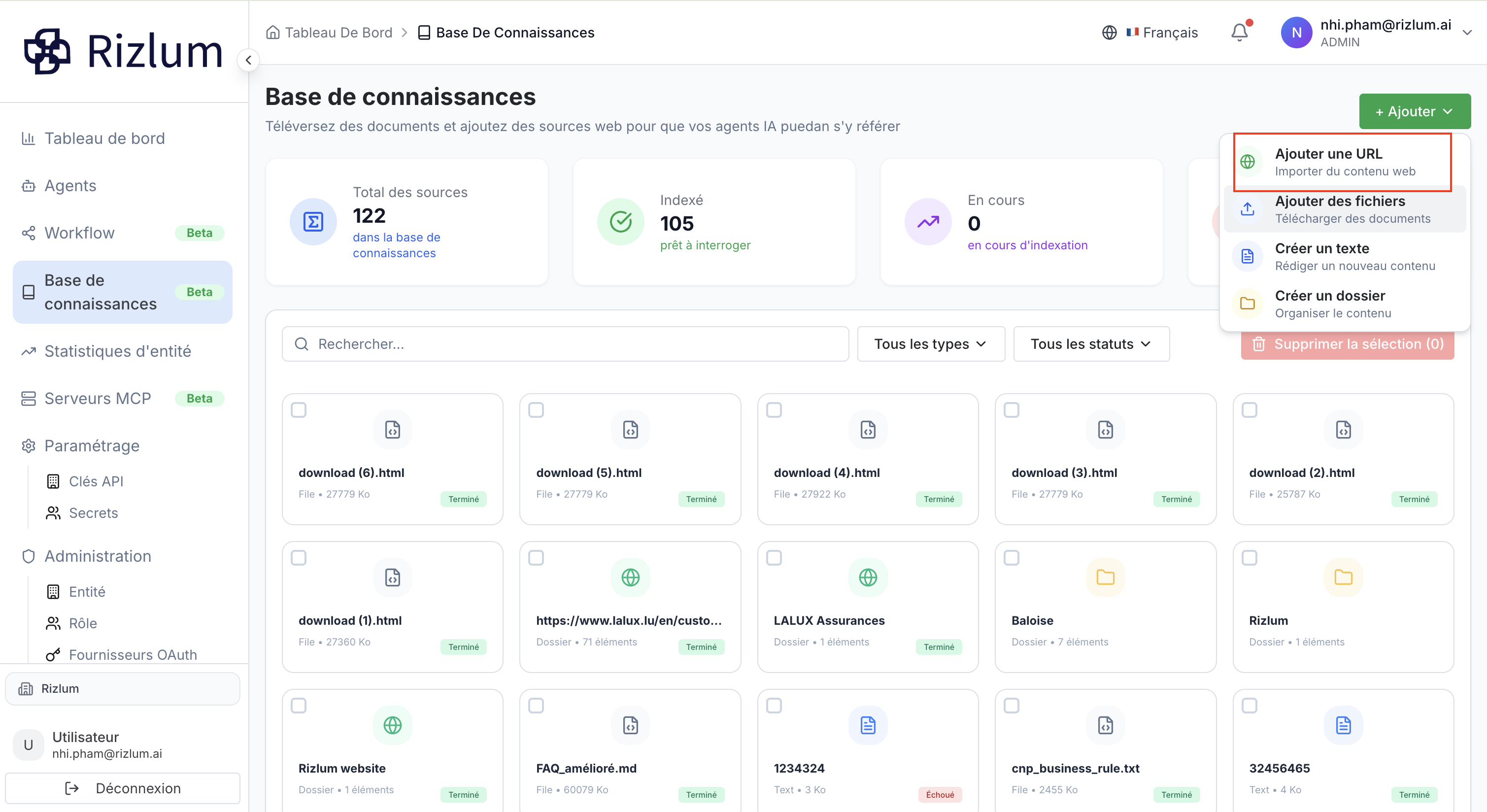
Le formulaire initial requiert le paramétrage des deux variables clés suivantes :
| Champ / Option | Statut | Rôle Fonctionnel et Impact RAG |
|---|---|---|
| NOM DE LA SOURCE | Obligatoire | Libellé personnalisé permettant d'identifier ce lot d'URLs dans le tableau de bord (ex : Rizlum page). |
| URL RACINE | Obligatoire | L'adresse web de base (le point d'entrée) à partir de laquelle le robot d'indexation va analyser le site (ex : https://rizlum.ai). |
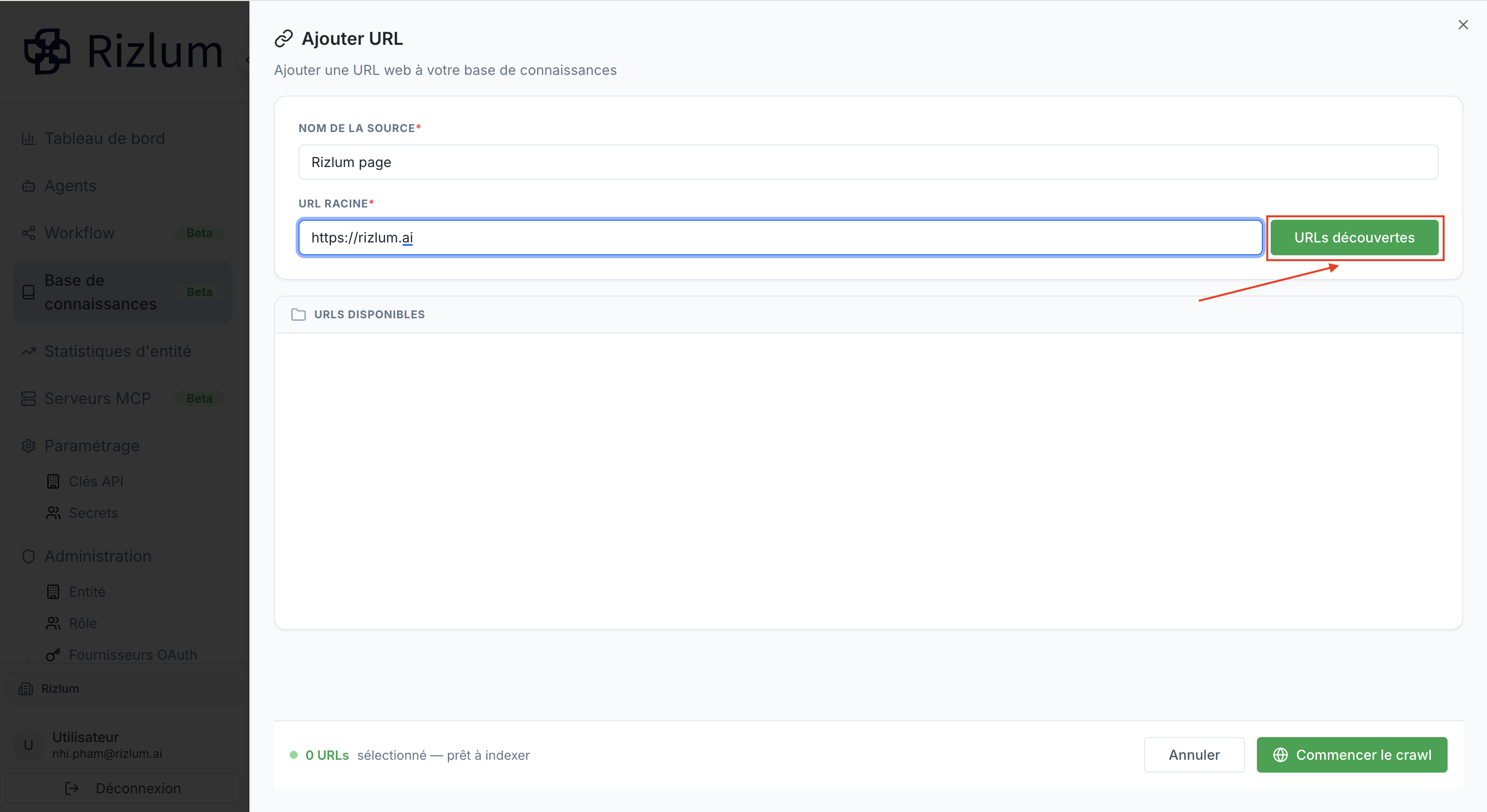
Une fois l'URL Racine correctement saisie, l'utilisateur doit déclencher l'analyse du site :
- Action : Cliquez sur le bouton vert « URLs découvertes » situé à droite du champ de saisie.
- Comportement du Système : Le robot de Rizlum effectue une requête d'analyse sémantique et technique sur l'URL racine. Il scanne la page pour identifier de manière autonome l'ensemble des sous-liens et pages secondaires associés.
- Résultat : Les adresses détectées sont automatiquement listées et provisionnées en contrebas, dans la section dédiée « URLS DISPONIBLES ».
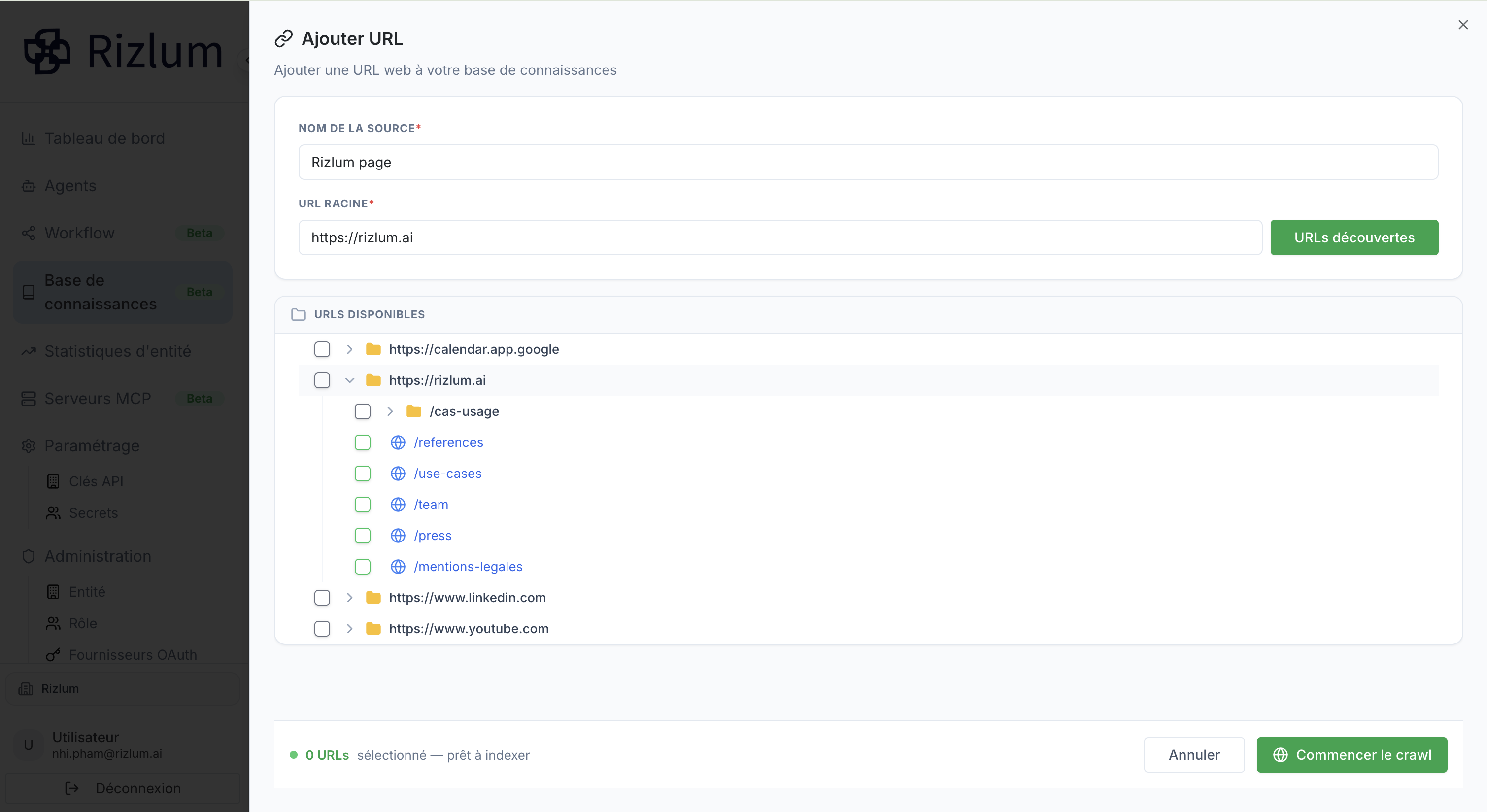
Le système ne charge pas automatiquement tout le site web, vous permettant de choisir précisément les pages à intégrer à votre base de connaissances. Vous pouvez naviguer dans l'arborescence en dépliant les dossiers à l'aide des flèches pour inspecter les sous-pages. Cochez simplement la case en regard des pages ou des répertoires pertinents (comme vos guides ou vos FAQ) pour les sélectionner, et laissez les cases des pages inutiles (comme les réseaux sociaux ou les mentions légales) décochées. Le compteur situé en bas à gauche se met à jour en temps réel pour indiquer le nombre d'URLs sélectionnées et prêtes à être indexées.
2.3.3. Créer un texte / un dossier
Le système vous permet d'alimenter votre base de connaissances en téléversant soit du texte brut, soit des dossiers complets de documents.
Ajouter un texte : Cette option vous permet de copier et de coller directement du contenu textuel (comme une note interne, une mise à jour de procédure ou une FAQ volante) sans avoir à créer un fichier au préalable. Donnez un nom à votre source, insérez votre texte dans le champ dédié, et validez. L'IA découpera et vectorisera ce contenu instantanément.
Créer un dossier (Dossier vide) : Cette fonctionnalité sert à organiser l'arborescence de votre espace de travail. Elle vous permet de créer un dossier vide afin de classer vos futurs documents par thématiques, par départements ou par types de fichiers (exemple: un dossier « FAQ » ou un dossier « Notices »). Vous pourrez ensuite glisser-déposer ou déplacer vos fichiers directement à l'intérieur pour garder une base RAG propre et structurée.
Une fois l'action validée, chaque élément est envoyé vers le pipeline RAG pour être traité, indexé et immédiatement mis à la disposition de vos agents Chat et Voice.